Simple python web server
Python搭建简易server实现生产消费模式的任务分配
1. 背景
在我们的监控系统中,需要每周跑一次100万场gamecore的任务来确保本周的游戏表现正常。对于这种计算密集型任务,自然是需要放到分布式的计算平台上去跑。因此,自然也需要一个任务分配规则来规定每个pod应该跑哪几场gamecore。我们可以用一个很简单直接的规则,假如总共用1000个pod,那么每个pod则需要跑100w / 1000场gamecore。只需要根据pod的唯一id来为每个pod平均分配好它的任务即可。但是这样的分配方式局限性比较大:在每个pod启动前就已经规定好了它需要跑的场次,如果这个pod挂掉,那么分配到它的对局就会丢失(假设pod没有重启机制,且每场对局都是不一样的)。另外,实际情况下并不是每个pod跑gamecore的情况都一模一样,有的可能会快,有的可能会因为各种问题卡住,所以这种分配方式也会导致很多跑完了的pod就空闲下来,等待未完成的pod去跑完它们的任务而不是帮忙完成任务。
因此,这其实是一个很典型的生产消费者场景。我们需要一个master来统一管理分发任务,每个worker每次都向master取一定数量任务,直到master那里所有任务完成。这样每个worker并不需要知道自己总共需要跑多少场gamecore,只要从master那里取不到任务时,则可以任务任务已经结束。实际上,只有master才知道什么时候任务已经完成。
这里需要注意的是,我们这个任务与一般机器学习的训练任务有所不同。我们的结束条件是跑完所有的100w场对局,是在任务开始之前就已知总共要跑多少对局。而机器学习训练则一般是根据某个参数是否达到阈值来判断训练是否结束,在训练开始前是不知道总共需要跑到少次对局。
2. 整体结构
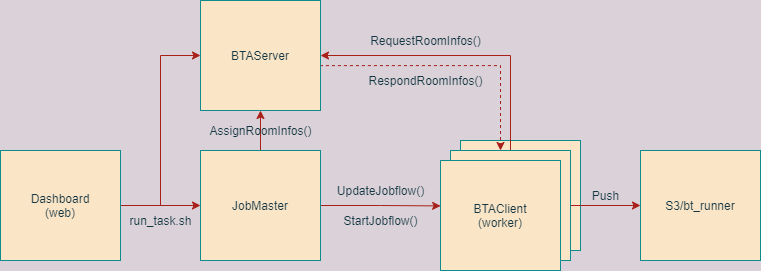
整个任务流程如图,在web上输入相应参数后,会通过启动脚本run_task.py来创建一个JobMaster和BTAServer,同时将输入的参数存入redis。其中BTAServer用于相应pod发过来的请求,并将该pod此次需要跑的任务返回给它。JobMaster则负责主要和K8s平台交互,通过读取redis里存入的参数,修改jobflow的参数并启动jobflow。同时,JobMaster里包括了管理此次任务的总体进度,即在AssignRoomInfos()函数将每个pod需要跑的任务,通过BTAServer传递给每个pod。
Jobflow起来之后,会创建若干个pod,每个pod都是一个worker。每个pod都会像BTAServer发送请求,获取它们此时需要跑的gamecore参数,然后自己完成自己的任务之后再次请求。当server处返回的值为空时,则表明此时总任务已经完成,worker则会停止请求,变为success,然后每个worker都会将自己产生的统计文件打包上传到s3上,供后续分析任务使用。
3. Server端代码
(1). 同步server
Python自带的http.server是一个基本的TCPServer框架(在python2中为BaseHTTPServer库),通过提供一个BaseHTTPRequestHandler类,可以实现对不同HTTP请求的处理。例如,每次有GET请求过来,则会实例化一次这个handler类,并调用对应的do_GET()来处理该请求。
import http.server
import json
from io import BytesIO
from job_master import JobMaster
class RequestHandler(http.server.BaseHTTPRequestHandler):
def __init__(self, job_master, request, client_address, server):
self.job_master = job_master
http.server.BaseHTTPRequestHandler.__init__(self, request, client_address, server)
def do_GET(self):
room_infos = self.job_master.assign_room_infos()
self.send_response(200)
self.end_headers()
response = BytesIO()
response.write(json.dumps(room_infos).encode('utf-8'))
self.wfile.write(response.getvalue())
if __name__ == '__main__':
serverAddress = ('', 8081)
master = JobMaster()
def myHandler(*args):
RequestHandler(master, *args)
server = http.server.HTTPServer(serverAddress, myHandler)
server.serve_forever()
上述代码用基本的http.server库实现了一个简单的server,可以响应通过TCP发送过来的HTTP的GET请求,并返回jobMaster中管理的当前任务场次信息给发送请求的pod。这里需要注意三点:
- 通过请求发送和返回的数据都是
byte类型,所以读取和写入的时候都需要注意转换为utf-8。 - 如果想要传入参数到我们自己的Handler里面,可以如上代码一样,再定义一个函数
myHandler(),将jobMaster在函数内传入给RequestHandler的构造函数,然后在手动调用基类的构造函数。 HTTPServer并不能异步处理请求,每一个请求都必须处理完才能处理另一个请求。request_queue_size则是表示的是请求队列的长度,默认为5。如果超过这个长度则会返回Connection denied错误。如果想要实现并发,则需要使用多进程或者多线程来处理请求,具体可以查看here。
实际使用该同步server时会有很多问题,其中最明显的就是耗时。测试发现这个server处理一个请求将会耗时0.14s,也就是说1s种只可以处理8个请求,这显然是不能接受的。我们可以通过log,看一下具体耗时在哪里:
- 从log看出,每个请求在server端处理完毕后,在返回到pod这里的耗时,大概有30ms,这显然是不太合理的。查看了server所在的地区和worker的地区,发现一个在华东一个在华南,跨地区必然会带来时间上的增加,所以第一步是将两者放到一个地区,以避免跨地区带来的开销。
- 在业务逻辑中,看到虽然有一些计算,但其实时间开销很少。其中会有4次调用
redis.set(),其中每次都会导致10ms的消耗,这显然也是不能接受的。因为每次set,都会完成一整次的和redis的通信,所以耗时会很高。这里可以采用redis提供的pipeline方法,一次set掉所有4个参数,就会只和redis通信一次。也可以直接采用多线程,将set操作放到一个新线程里处理。后续我们采用多线程的方法。
(2). 异步server以及问题调试
因为我们在assign_room_infos()函数中会将当前总共跑了多少场gamecore等数据存入redis的操作,实际上会比较耗时,所以基本的同步server并不能满足我们的需求。因此,我们需要使用ThreadingMixIn类来实现异步请求处理。
import http.server
import socketserver
import json
import urllib.parse as urlparse
from io import BytesIO
from job_master import JobMaster
logging.getLogger().setLevel(logging.INFO)
logging.basicConfig(format='[%(asctime)s][%(levelname)s][%(module)s::%(lineno)d]: %(message)s',
datefmt="%Y-%m-%d %H:%M:%S",
filename='server_log.txt')
request_stack = 0
request_count = 0
class ThreadedHTTPServer(socketserver.ThreadingMixIn, http.server.HTTPServer):
pass
class RequestHandler(http.server.BaseHTTPRequestHandler):
def __init__(self, job_master, request, client_address, server):
self.job_master = job_master
http.server.BaseHTTPRequestHandler.__init__(self, request, client_address, server)
def do_GET(self):
# check task_id
global request_count
global request_stack
request_count += 1
request_stack += 1
start = time.time()
parsed_path = urlparse.urlparse(self.path)
request_id = parsed_path.query.split('=')[1]
logging.info('Start deal with request: {}, request_count = {}, request_stack = {}'.format(request_id, request_count, request_stack))
room_infos = self.job_master.assign_room_infos()
self.send_response(200)
self.end_headers()
response = BytesIO()
response.write(json.dumps(room_infos).encode('utf-8'))
self.wfile.write(response.getvalue())
request_stack -= 1
logging.info('End deal with request: {}, request_count = {}, time consuming = {}, request_stack = {}'.format(request_id, request_count, time.time() - start, request_stack))
if __name__ == '__main__':
serverAddress = ('', 8081)
master = JobMaster()
def myHandler(*args):
RequestHandler(master, *args)
server = ThreadedHTTPServer(serverAddress, myHandler)
server.serve_forever()
从代码上可以看到,我们只需要继承这个ThreadingMixIn类则可以通过多线程来实现请求的异步处理。每次有新的请求到来时,都会产生一个新的线程来处理这个请求。但是,在实际测试中,发现一旦pod数量超过100(最大可能同时有100个请求来到服务端),就总是会有一些请求会丢失掉。具体的表现为worker这边发送了请求后,长时间没有收到回复,导致出现timeout错误。为此,我们需要通过log来检查到底是哪里出了问题(看代码)。
首先,我们需要知道客户端这里到底有没有发送请求,以及server端到底有没有接受到请求。所以我们给客户端发送的每个请求都加上一个唯一id,并在服务端这里解析id打印出来。结果显示,客户端确实每次都成功发送了所有的请求,但是服务端却并不是每个请求都成功分发到了GET方法。也就是说,服务端总是会有部分请求丢失。
然后,初步怀疑是因为同时请求过多导致了服务端不能处理,这可能是由于linux系统某些系统参数设置导致。所以我们增加了两个全局变量request_count和request_stack来记录到达服务端的请求情况。其中,每到达一个请求,则request_count和request_stack都加1,每处理完一个请求request_stack减1。如果是因为socket参数的设置导致一些过多的请求会被丢弃,那么我们只需要观察每次丢失请求时,request_stack是不是都会到一个比较接近的值。
同时,为了方便测试,我们需要一个能够异步发送请求的脚本,来模拟多个pod同时请求的情况。Python3中的asyncio携程可以很好的满足需求。
import sys
import os
import logging
import subprocess
import json
import time
import requests
import threading
import asyncio
from aiohttp import ClientSession
from requests import exceptions
from requests.adapters import HTTPAdapter
logging.getLogger().setLevel(logging.INFO)
logging.basicConfig(format='[%(asctime)s][%(levelname)s][%(module)s::%(lineno)d]: %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
request_id = 0
class Worker():
async def get(self):
session = ClientSession()
global request_id
request_id += 1
logging.info('Worker: request roominfo, {}'.format(request_id))
res = await session.get('http://9.xx.xx.xxx:8081')
result = await res.text()
await session.close()
return result
async def request_room_infos(self):
global request_id
request_id += 1
data = {'request_id': request_id}
room_infos = {}
try:
t1 = time.time()
logging.info('Worker: request roominfo, {}'.format(request_id))
r = await self.get()
t2 = time.time()
except exceptions.Timeout as e:
logging.error('Time Out: ' + str(e))
except exceptions.HTTPError as e:
logging.error('Http Request Error: ' + str(e))
except exceptions.ConnectionError as e:
logging.error('Connection Error: ' + str(e))
else:
logging.info('Request room infos time consuming = {}s'.format(t2 - t1))
if r.status_code == 200:
room_infos = r.json()
else:
logging.error('Request Error: ' + str(r.status_code) + ',' + str(r.reason))
return room_infos
def run_gamecore(self, sleep_time):
time.sleep(sleep_time)
if __name__ == '__main__':
worker = Worker()
request_count = int(sys.argv[1])
tasks = [asyncio.ensure_future(worker.request_room_infos()) for i in range(request_count)]
start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
logging.info("Coroutine tasks finished, time = {}s".format(time.time() - start))
logging.info('Task finished!!! Run {} games in total.'.format(worker.total_finished_room_count))
上述测试脚本,模拟了多个pod同时给server端发送请求的情形。但是很遗憾,通过测试脚本发现,即使只是100个请求,server端也会丢弃掉20个左右的请求。虽然log显示request_stack最大能够到1000多,但是实际上能够同时处理的请求最大也就到80个左右。并不知道是因为什么原因导致了请求丢失,怀疑可能是Linux某些系统设置导致了请求直接被丢弃。比如net.core.somaxconn参数表示的是系统同时发起的TCP连接数,超过时会导致超时或者重连。我尝试着将这些参数都改大(具体参数说明):
echo "net.ipv4.tcp_max_syn_backlog = 40000" >> /etc/sysctl.conf
echo "net.core.rmem_max = 52428800" >> /etc/sysctl.conf
echo "net.core.wmem_max = 52428800" >> /etc/sysctl.conf
echo "net.core.somaxconn = 10240" >> /etc/sysctl.conf
echo "net.ipv4.tcp_timestamps = 0" >> /etc/sysctl.conf
echo "net.ipv4.tcp_sack = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_window_scaling = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_fin_timeout = 15" >> /etc/sysctl.conf
echo "net.ipv4.tcp_keepalive_intvl = 30" >> /etc/sysctl.conf
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf
echo "kernel.core_pattern = /data/corefile/core_%e_%t" >> /etc/sysctl.conf
echo "kernel.core_pipe_limit = 0" >> /etc/sysctl.conf
sysctl -p
还是很遗憾,这些改动并没有太大作用,测试发现同时100个请求,还是会丢失20个左右,较之之前并没有太大改动。我也试过修改http.server框架的request_queue_size参数,结果也是一样。不知道这里是不是我哪里设置有问题,如果哪里不对请告诉我。另外因为是TCP连接,总不会是丢包吧?所以只能抓抓包看看是不是TCP连接的时候就有问题。

使用tcpdump抓包后在用wiresharkGUI工具在本地跟踪流,通过之前的request_id定位到那些发送出去,但是server端没有收到的连接,跟踪发现它们确实在第一次握手之后,客户端发送出了HTTP请求,然后服务端直接给拒绝了,并置了RST包。到此,我还是不知道到底是什么原因导致了server直接返回了RST。但是这里可以确定的是,这确实是因为系统或者框架自身的原因导致了请求直接被拒绝,与业务逻辑无关。所以如果有人知道这里具体是什么原因,也请通过左侧导航栏邮箱告诉我,或者直接在下面留言,查了几天都没有结果,真的很想知道是什么原因。
(3). Tornado异步server
虽然不确定到底是系统的问题,还是http.server框架自身的问题(或是使用框架的方法不对),但是因为与业务逻辑无关,所以决定尝试换一个第三方框架试试。Tornado是一个python上多进程非阻塞式server框架,很适合我们这种可能同时有上千个请求同时到达的场景。
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
import json
import logging
import time
from job_master import JobMaster
from tornado.options import define, options
define('port', default=8081, help='Running Port', type=int)
logging.getLogger().setLevel(logging.INFO)
logging.basicConfig(format='[%(asctime)s][%(levelname)s][%(module)s::%(lineno)d]: %(message)s',
datefmt="%Y-%m-%d %H:%M:%S",
filename='server_log.txt')
request_stack = 0
request_count = 0
class IndexFun(tornado.web.RequestHandler):
def initialize(self, job_master):
self.job_master = job_master
def get(self):
request_id = self.get_argument('request_id', '-1')
global request_count
global request_stack
request_count += 1
request_stack += 1
start = time.time()
logging.info('Start deal with request: {}, request_count = {}, request_stack = {}'.format(request_id, request_count, request_stack))
room_infos = self.job_master.assign_room_infos('999')
self.write(json.dumps(room_infos))
request_stack -= 1
logging.info('End deal with request: {}, request_count = {}, time consuming = {}, request_stack = {}'.format(request_id, request_count, time.time() - start, request_stack))
if __name__ == '__main__':
tornado.options.parse_command_line()
master = JobMaster()
app = tornado.web.Application(handlers=[(r"/", IndexFun, dict(job_master=master))])
server = tornado.httpserver.HTTPServer(app)
server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
与http.server类似,tornado同样提供了一个requestHandler来处理各种请求。我们也可以通过重写initialize方法来将jobMaster参数传入到这个handler类中。使用上述的测试脚本对该server进行测试,发现该框架下最高可以同时处理5000个请求而没有出现请求丢失的情况。从这里看,之前的问题可能还是和server框架本身有关。最终,决定采用该框架作为服务端代码。
4. Client端代码
客户端直接使用requests库即可:
import sys
import os
import logging
import subprocess
import json
import glob
import shutil
import time
import random
import requests
from requests import exceptions
from requests.adapters import HTTPAdapter
from util import *
from tenc_config import TENC
logging.getLogger().setLevel(logging.INFO)
logging.basicConfig(format='[%(asctime)s][%(levelname)s][%(module)s::%(lineno)d]: %(message)s', datefmt="%Y-%m-%d %H:%M:%S")
request_id = 0
class Worker():
def __init__(self, run_id):
self.run_id = run_id # todo: 同时跑多个任务时用于区分不同任务
self.worker_name = get_worker_name()
self.total_finished_room_count = 0
self._json_file_dir = None
self._byte_file_dir = None
def _exec_cmd(self, primary, args):
# cmd = primary + args
cmd_str = primary + ' ' + ' '.join(args)
logging.info(' --- ' + cmd_str + ' --- ')
output = subprocess.check_output([primary, *args])
return output
def request_room_infos(self):
global request_id
data = {'request_id': request_id}
room_infos = {}
try:
t1 = time.time()
logging.info('Worker: request roominfo, {}'.format(request_id))
r = requests.get(TENC.dashboard_ip, params=data, timeout=None)
t2 = time.time()
except requests.exceptions.Timeout as e:
logging.error('Time Out: ' + str(e))
except requests.exceptions.HTTPError as e:
logging.error('Http Request Error: ' + str(e))
except requests.exceptions.ConnectionError as e:
logging.error('Connection Error:' + str(e))
except ConnectionResetError as e:
logging.error('Connection Reset Error:' + str(e))
except OSError as e:
logging.error('Built-in Timeout Error: ' + str(e))
else:
logging.info('Request room infos time consuming = {}s'.format(t2 - t1))
if r.status_code == 200:
room_infos = r.json()
else:
logging.error('Request Error: ' + str(r.status_code) + ',' + str(r.reason))
request_id += 1
return room_infos
def run_gamecore(self, room_infos):
pass
if __name__ == '__main__':
worker = Worker()
while True:
room_infos = worker.request_room_infos()
if len(room_infos) == 0:
break
worker.run_gamecore(room_infos)
logging.info('Task finished!!! Run {} games in total.'.format(worker.total_finished_room_count))
logging.info("Start pushing zip files to s3:")
worker.push_data()
logging.info("Pushing zip files successed.")
至此,服务端和客户端代码都已经实现。服务端支持同时异步处理最大5000个请求而没有丢失。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 gzrjzcx@qq.com
文章标题:Simple python web server
文章字数:4.2k
本文作者:Alex Zou
发布时间:2021-06-15, 15:17:32
最后更新:2024-07-10, 03:02:36
原始链接:https://www.hellscript.cc/2021/06/15/subposts_tools/simple-python-web-server/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

